

What happened to Big Data?
What happened to Big Data?

A post-mortem of a former buzzword for non-techies
I love this quote from Dan Ariely, that used to describe the nature of Big Data in business:
“Big data is like teenage sex: everyone talks about it, nobody really knows how to do it, everyone thinks everyone else is doing it, so everyone claims they are doing it.”
What was true for Big Data in 2013 is not true anymore only four years later in 2017.
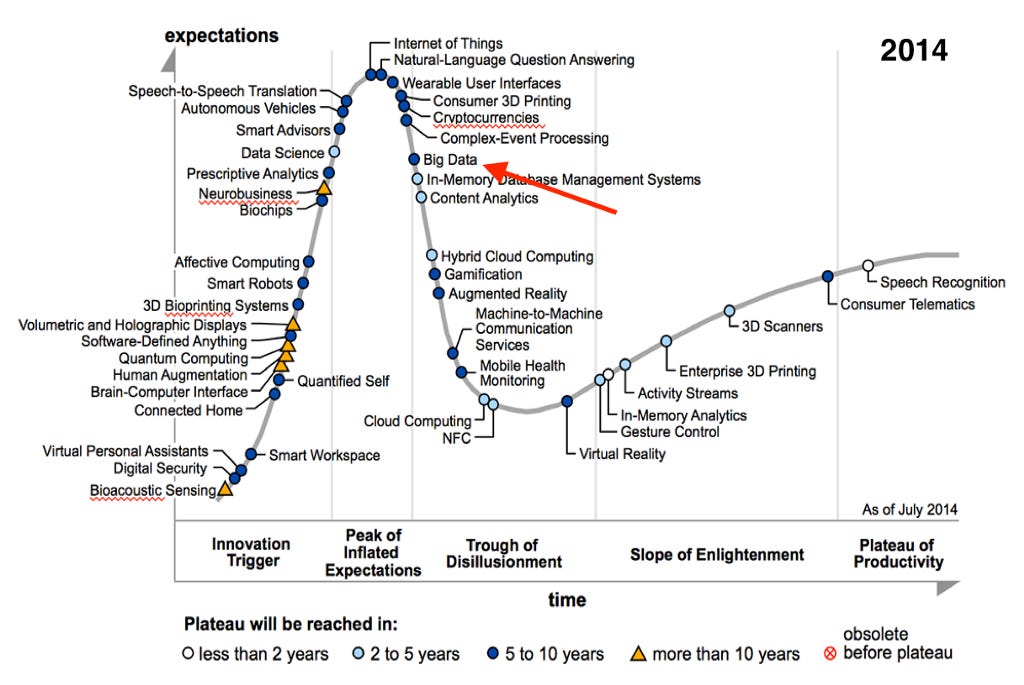
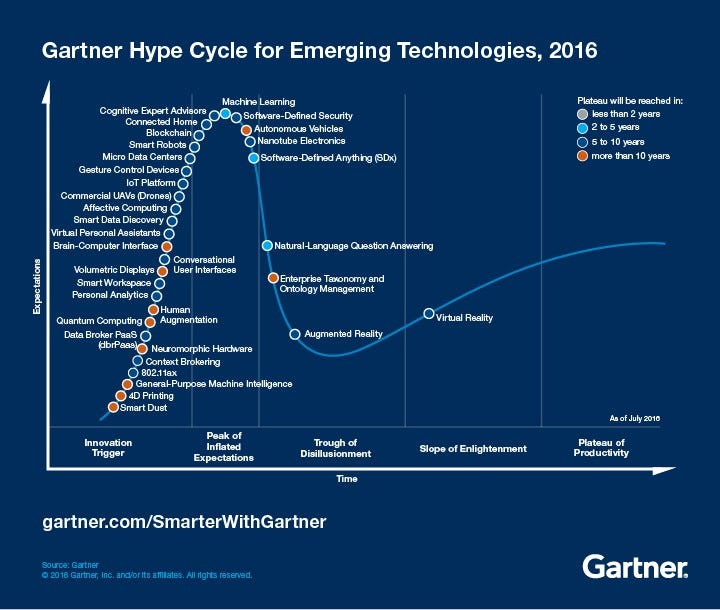
Big Data has just vanished from the landscape, this is a good thing since it looks like it has become the status quo to make use of big data. In order to look at how we have come this far, let’s look at the history where “Big Data” comes from, and what it actually means.
Big Data 0.0 to 1.0
Here is how an increase of database size was handled in the past:

Traditionally, we used vertical scaling in order to handle higher perfomance requirements and ever growing databases. However, the cost of improving one computer rises exponentially after reaching a certain performance level and is therefore very unscalable. Horizontal scaling in contrast distributes the storage and computation amongst many computers. The key advantage is that the economies of scale behind commodity hardware makes horizontal scaling a much more attractive option.
Big Data means working with data that doesn’t fit or can’t be processed by one computer alone.
This definition is important, because it explains why Big Data never was anything special from a technical perspective. The challenge has always been solely to bring capabilities that are available on one computer to a cluster of computers. In the early days this was a rare ask where people manually wrote Perl scripts that spawned workers within the nodes of clusters. There was a huge need to simplify this process.
Chapter 2.0: Simplify Distributed Batch Processing
The company that really kicked this movement off was Google by publishing two hallmark papers: One on the Google File System (2003) and the other on Google MapReduce (2004). These papers inspired the creation of Hadoop (named after the plush toy of the Doug Cutting’s son), where the ideas of the Google papers were implemented and open-sourced. Now, suddenly the world had a powerful abstraction tool to store data in a distributed matter as well as MapReduce to crunch the data. This abstracted away all the difficulties of distributing tasks among nodes in a cluster.
Chapter 2.6: Diffraction of MapReduce to multiple specialized engines

This new approach was optimized for batch data processing, Businesses however couldn’t wait for a batch computation to complete and had applications that required different set of functions (apart from map, reduce and filter). Imagine your company cluster being maxed out for 8–20 hours for a single large scale computation to run. In addition, MapReduce is not user friendly and takes much This caused multiple projects to spawn that were able to overcome specific shortcomings of MapReduce.
However, with many specialized engines a new set of challenges was found
maintenance of multiple software stacks
interaction between systems is difficult and resource intensive
it is very hard to optimize these systems and share data between them
The question was now, whether we would get back to a more universal engine.
Chapter 3.x: Spark
A team of the infamous (and now dissolved) AMPlab at UC Berkeley developed Spark as a unified engine that is more general and utilized the memory. Ergo, it is way faster (10x to 100x), way more powerful and easier to use. Today, Spark is the de-facto industry standard engine for Big Data. In terms of performance, Spark has been able to take out the HDD as the major Bottleneck. Spark 2.0 was released in mid-2016 and there is no sign that it’s development will slow down.

2016 is the year when Big Data reached its position as “business-as-usual”. The platforms that are continued to be improved are more available and not just restricted to few early movers. Not only has it become more accessible in terms of required skills, it is also cheaper than ever to deploy a Spark cluster on for example Amazon AWS.
The world has moved on to new buzzword topics: Artificial Intelligence.
What happened to Big Data? was originally published in Hai Nguyen Mau on Medium, where people are continuing the conversation by highlighting and responding to this story.